Explorer v1.3
Introduction
TickStream.CV Explorer is a desktop application that allows an analyst to compare freeform typing samples collected by the TickStream.Activity Client. The comparisons can be used to determine whether the samples were typed by the same individual.
System Requirements
TickStream.CV Explorer performs its processing on the machine it is running. You should have sufficient CPU and memory resources.
- Microsoft Windows 7 / Windows Server 2008 R2 and later
- Microsoft .NET Framework 4.0 or later
Database Connectivity
The Explorer application must have network access to the TickStream.Activity SQL server. This may be configured from the Options menu in the application.
Quick Start
For this program to produce usable results, you must already have been running TickStream.Activity, with a Unity license, for long enough to have collected the necessary text for at least two usable samples. Start by selecting two sample sets. You can do more later. While there is no programmatic limit on the number of simultaneous sample sets that can be evaluated in one run, there are considerable design, processing-time and results-comparison reasons that suggest four as a maximum practical number of sample sets in any one run.
Before launching this application, you must connect to your SQL server. The manner of this connection can vary from one environment to another, and thus might require the assistance of your Systems Administrator.
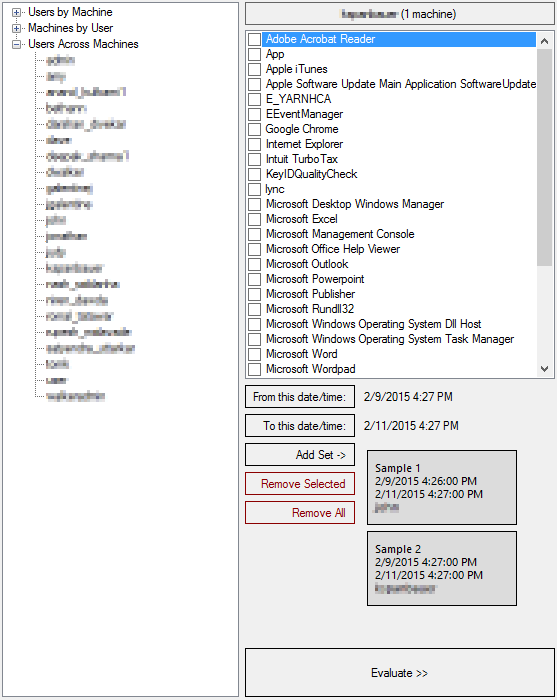
Once launched, TickStream.CV Explorer will automatically present the names of all of known user and machine names which have participated in the collection process, as well as the names of all applications which each user has run, organized by machine. First, select a Machine/User pair. Then double click on that selection. That will cause the list of used applications to appear. Make any desired user/application selections, or leave all checkboxes unchecked, and it will include keying data from all applications in the sample set.
Next, choose a start/stop time range for each sample (those can be the same or different time ranges, but must NOT overlap for any one user). Then press the Evaluate button. Depending upon the amount of text, the number of users and the processing power of your PC, it might take some time for the results to appear. You will see that there are an amazing number of complex calculations made — often numbering well into the millions. Advancement toward completion is indicated by several progress bars. Please note that before any movement on the Process Bars is seen, there is an extensive transfer of data taking place between the SQL server and this application. During that time, the wait cursor will appear.
When the results are available, the several tabs in the display area will contain a wide variety of data which statistically indicate the likeliness of a match (or matches). A summary of the returned data is at the end of this FAQ. However, details about the contents of those return-data tabs, as well as a comprehensive discussion of how to interpret the information they present, is too long and involved to cover in this Help/About page, but is separately available.
About TickStream.CV
What Is It? TickStream.CV is software that enables the continuous validation of a user’s authenticated identity. It is ideal for detecting insider threats, recognizing “keyboard sharing,” and frustrating the efforts of impostors to perform many kinds of everyday activities on PC’s pseudonymously, among many such requirements.
Normal typing produces a string of characters (“content”). What the act of typing also does, unknown and unobtrusive to users, is to make available a large number of metrics about HOW and WHEN such typing occurred. These descriptive metrics, which TickStream.CV analyzes, contain no content, only patterns and timing data. For years we have researched the question of whether a given user’s overall keyboard-usage metrics are unique. We found that they are. We then submitted our data to qualified, nationally-recognized, experts to have them review our work and conclusions. TickStream.CV can compare two separate assortments of qualifying text (selected by a TickStream.CV customer, herein called the Host) and accurately opine as to whether they were created by the same person. To be clear, when the Host “selects” the text, that act is only to point out which two sets of existing typing (from which applications or some other way of grouping characters) the Host wishes to have TickStream.CV evaluate for author sameness. While TickStream.CV Explorer is a forensic tool, meaning that it only looks at events from the past, it is easily possible for TickStream.CV’s evaluating actions to occur on a near real-time basis (e.g., was the paragraph "just typed" done by the author of the Cadence & Habit Library created by a known person?). Unlike a security camera which records continuously but needs a person to form a judgement about the activity in the recording, TickStream.CV can do both.
TickStream.CV provides sufficient information to help determine when another person is at the keyboard during the same login session. Keyboard-sharing and credentials-sharing are serious issues in many business contexts. Once login has happened, until now organizations have had no reliable way to detect if the operator of a PC has changed. TickStream.CV offers a good, workable, affordable, nearly frictionless solution. The only cross-application hardware that is universally in-place, and found to be reliably useful, is the keyboard. Some have asked about the mouse, but through extensive testing, IA has not been able to discern repeated mouse movement patterns which are sufficiently similar to work for the purpose of dependable authentication. This is principally because: (a) mouse travel is variable — the places clicked often change from display to display; (b) relative to the single hover point which the mouse ""knows about"", the size of the destination click target (e.g., a Submit button) is big — this accommodates ease of use, but allows for a widely varying range of successful x,y click points; and (c) the x,y coordinate point pick-up by varying types of mice are randomly affected by the surface over which the mouse travels. But the keyboard does not have those problems, and almost everybody types almost all the time. By comparing the Cadence & Habit of current keying activity with a Library containing the typing history of the rightful user, assuming only that a reasonable number of appropriately-typed characters are available and suitable, TickStream.CV can tell if there is a different user. The purpose is to provide an excellent tool for continuous validation.
How is it deployed? TickStream.CV works over the web, or can be installed on Windows PC’s or tablets. TickStream.CV-harvested text is sent to a server connected by standard web services. In web applications, the text metrics are captured with just a few lines of straightforward HTML that are easily embedded in applicable web page code. In desktop applications, we provide a small program, which can be turned on or off based on Host Business Rules, which frictionlessly gathers text metrics from any application that runs on the desktop. Either way, the users' typing results in the creation of a Cadence & Habit Library, either initially up front, or, with TickStream.CV, more likely over time during normal use. At any time, comparisons can be made between current activity, and trusted historical Library metrics. Text capturing functionality can be windowed by time, application or other user-defined criteria. The validating polling cycle, the source(s) of the requisite text collections, and the amount of text which would trigger an evaluation are all controlled by the Host.
How is it used? Like all IA software, its lifecycle has three stages: (1) Collection, (2) Evaluation, and (3) Reporting. The second (2) Evaluation stage is completely automatic and requires nothing from users after initial installation. The first and third stages are designed to cooperate with users' (Host) Business Rules: (1) at what point(s) in everyday practice will the users' typing metrics be captured? (3) When should Reporting occur? In other words, what subsequent typing activity (application and quantity) should have transpired before a decision as to user authentication is requested? Meaningful use of TickStream.CV-reported results obviously depends on the quantity of Instance text, once a robust Library has been created. Clearly, for example, it is not possible to authenticate somebody by means of a single character in a statistically-meaningful sense. On the other hand, just the text in a one normal email containing several paragraphs can often produce usable results. TickStream.CV technology shines impressively at the far end of that spectrum, with certainty in the near-100% range when a lot of text is involved (e.g., comparing the typing of a student’s exam with the typing that she previously did in her routine homework submission and other communications with the professor during the course).
Enrollment. All that is required is a sufficient quantity of the two (or more) text collections which are to be compared. The Host (a) can require that a base set be created in a formal process initially before any PC use begins or, more likely, (b) can simply specify when, where and how the base collection was captured, ad hoc, over time. The details of that process can only meaningfully be supplied when the Host’s Business Rules are published, so no general how-to is contained in this document.
Technology. TickStream.CV works by identifying unique text segments which we call Hallmarks. Hallmarks have reliably, and broadly distinctive, characteristics which differ from each other first by the number of characters and string placement in the source text, and then by various timing elements gleaned from the way in which those letter groups were keyed. Hallmarks are said to be alike when their component patterns are highly coherent OR consistently random. A very considerable number of statistical operations are performed to select from a user’s total text-generation activity the “best” idiosyncratic patterns. These are the ones which occur at the far ends of several coherence/randomness variance spectrums which are dynamically created for each user. The prevailing Hallmarks in an Instance sample are then “matched” to equivalent ones in the user’s Cadence & Habit Library using separately-patented geospatial mathematical procedures. As the number of Hallmarks that can be used in forming user-sameness statistics increases, so does the probability of result certainty. While nearly everyone in the world can type, say, “k” the way you do, no one in the world can intentionally and purposefully type a full page the way you did … interestingly enough, including yourself during a subsequent attempt. What makes our math exceptional is that we can recognize you even given your varying samples, but successfully distinguish you from others.
Reporting. The TickStream.CV Reporting phase is truly unique and instantly understandable. TickStream.CV provides a comprehensive suite of numerical analytics, as well as three “sub-three-second” graphics: (1) is there enough text?, (2) are there sufficient compare-worthy text quantities?, and (3) do the overall, behavior-matching, dashboard-like, drawing elements sufficiently match? The wrong person’s tracings stick out just as much as earthquakes' ones do on a seismology machine when compared to quiet times.
Accuracy and Performance
Most computer programs need only follow one rule: "Perform professionally, accurately, easily, completely and quickly, all in a trustworthy manner." TickStream.CV must also follow a second rule: "Obey the laws of statistics."
IA alone is responsible for Rule One, but IA and you, the user, share the responsibility for meeting the requirements of Rule Two together.
Authentication is of two types: deterministic and probabilistic. Deterministic is a pass/fail concept. You were either born in Minnesota. Or not. That fact can be determined absolutely. Probabilistic is a variable concept infused with low and high chances — but not certainties. Children who are well loved and well fed are likely to do better in school than those unfortunate ones who grow up in fear and hungry. To be sure, there exist stark examples of success and failure at both ends of that spectrum, but the odds are …
That’s what “probabilistic” is all about. TickStream.CV is probabilistic. It’s about the odds that two separate collections of typed text were created by the same person. Or not. Human behavior — the best biometric — is never 100% certain, but most repeated behaviors, like the order of brushing teeth, or typing frequently-occurring characters, is reflexively habitual. With typing, it’s also predictable and distinctive. Over the course of a significant amount of regular, normal, subconsciously-driven typing, the patterns become increasingly unique, thus the higher the probability that a given set could — statistically speaking — have only been typed by one single individual.
There are two foundational requirements concerning the statistics of probability: (1) truly random sampling; and (2) having enough data. Those are the realities of raw mathematics and have nothing to with the way TickStream.CV program code performs. IA’s code must follow those calculation rules. And it does. But in the real world, there are a number of other realities, many of which are just common sense, and several others of which have to do with how TickStream.CV operates in a normal computing environment.
Here are two quick examples to illustrate some of the foregoing. Following that is a short summary of the “reality rules.” Understanding those is sine qua non to understanding what TickStream.CV is telling you.
Not enough data. You type the letter “k.” Someone else types the letter “k.” Those erstwhile ‘sample sets’ are then compared. Say they match 100%. Each user then went on to type thousands of other characters, but only the first “k” character of each was compared. Same person? Who knows? There is not enough data to know either way as to whether the k’s were typed by the same person. Or not.
Real world factors. You’re counting on TickStream.CV to compare two sets of typing. TickStream.CV “just has to come through” for you — it’s a demanding Use Case. But TickStream.CV did not answer the question. Why? Suppose that access to TickStream.CV‘s server — required to obtain information from the Cadence & Habit Library — failed because the internet was temporarily down. Therefore, “TickStream.CV failed.” Or not. Obviously TickStream.CV has no control over many real world circumstances. Most importantly, TickStream.CV has no “control” over how someone types; simply the expectation that they typed as they usually do: straightforward, non-experimentally, automatically, typically, comfortably, etc. … you get the idea.
Although the above two examples rather trivially illustrate problems at the simple end of things, they nevertheless show that many real world events and activities must happen correctly in order for TickStream.CV to perform. If they do, TickStream.CV will perform.
Below are some lists with brief descriptions of the most common real world problems.
Factors which make it difficult or impossible for TickStream.CV to return a usable/statistically-meaningful result:
- Ab initio bad identity. Remember that authentication is not, per se, identification. However, when someone has been properly identified, then subsequently authenticating that same person is the functional equivalent of identification. It follows the Associative Law of mathematics. Identification: Who they are. Authentication: Is that the same person as before?
- Outside problems. These range from fire, power, loss of the Internet, DoS (Denial of Service attacks), equipment failure, among many others.
- Futuristic robots successfully trained and “seated at the keyboard. ” If ever they come to be trained to be exactly you, then they are your digital doppelganger and TickStream.CV won’t help. Good luck.
- Rootkits. By definition, they run outside the operating system. The OS defines TickStream.CV’s Schwarzschild Radius — the edge of its “sphere of knowledge” — except this time the Black Hole is on the outside.
- Viruses and malware. Use a good anti-virus/anti-malware program.
We have defenses that can be put in place to address many of these, and staying ahead of worldwide cybersecurity assaults is an ongoing task.
Factors which make it difficult for TickStream.CV to perform as desired, or which cause the typist significant difficulty typing appropriately/usefully:
- Faulty business rules design.
- Incomplete or faulty business rules management (e.g., allowing infinite tries).
- Failed collection plan and/or collection circumstances.
- Different nature of the samples compared.
- Statistically unusable sample sizes.
- Sample size entropy. This is a challenging topic to grasp quickly, but basically holds that an infinite amount of typing over an infinite amount of time produces unremarkable (e.g., non-user-defining) data. Too little typing and the statistics fail. Too much typing and the data fails. We continue to work to define the Goldilocks Zone.
- Inconsistent typist / physical-incapacity. Something greater that 0% of the world’s population cannot type, or have situations and conditions that render their muscle movements sufficiently random that no personally-authenticating hallmarks are dependably produced. We have no TickStream.CV solution for those people (including, for example, people without hands). For that, to create a “100% Solution,” other technologies and/or management processes will have to be employed.
- Extreme environmental situations. These can make typists so uncomfortable that their efforts become abnormal, and hence of little meaningful value to TickStream.CV.
- People’s innate propensity to test. This is troublesome because testing represents a conscious effort to be different than usual: “What if I just slow down a bit?” or “What if we alternate users to see what happens?” Answer: no worthwhile results. IA has other technologies and processes to help address these concerns, but those lie in other products which are not described in this document.
- Seat-switching during enrollment / unmanaged enrollment. Same comment as above.
- Tuning represents a solid path to significantly increasing the sharpness of the statistics computations and the results that they produce. No external tuning capability is included with this release of TickStream.CV code.
Factors affecting a typist’s ability to “perform naturally” (both personal and external causes):
- Extreme fatigue and circadian considerations.
- Typist integrity failure.
- The "practice effect" (aka, repetition poisoning — frequent typing not random enough).
- Stage fright during artificial testing.
- Non-existing or ineffective sample collection monitoring plan; faulty user attribution.
Statistical Processing
Factors affecting statistical conclusions:
These are general rule statements. Understanding the reasons behind the nature, sequence, and extent of the statistical processing done by TickStream.CV is beyond the scope of this document, but may be separately available. However, it is nevertheless vitally important to understand how the many statistical decisions are made in order to evaluate the operation and performance of TickStream.CV and the usefulness of its results:
- At least two samples are required to make a comparison.
- Their order of selection (and the time ranges they span) is unimportant.
- Sample sets for the same user cannot overlap; different users can be compared over the same date ranges.
- Each sample must independently meet all size and other qualification criteria.
- Each sample set should contain random typing – not created with text read off a card, or entered into a form, etc.
- It is best when all typing is done without special thought (i.e., no character-by-character read/type intentional effort, like copying a complex chemical formula, etc.).
- Ideally, each sample set should contain mostly naturally-occurring words, using frequent, everyday, typing patterns.
- Also ideally, the same source application type would be used for both samples (e.g., Outlook) although applications that have the same basic typing behavior (e.g., Outlook and MS Word) would also work. On the other hand, comparing the typing done during, say, writing software programs is unlikely to match successfully with, say, the typing involved in entering numbers in MS Excel. This is more important in small samples. Larger samples contain enough characteristics that they are less affected by this constraint.
- A full range of characters is preferred (unlike MS Excel, which normally has mostly numbers).
- Special characters are ignored (e.g., function keys, numeric keypad, etc.). Also, there is no need for TickStream.CV purposes to backup and correct misspellings. TickStream.CV does not look at content, only effort.
- Special additional typing “quality guardrail” concerns:
- Multi-user pollution must be avoided. Any mixing of typists during a single typing-collection effort would be statistically invalid and deliver results which would not be trustworthy.
- As mentioned above, incompatible source applications should be avoided when reasonable.
- There must be user integrity at all times during testing (overcoming the human tendency to want to test the edges and experiment). Testing can be done in a well-monitored lab environment, but should not be done using any portion of creating the evaluation sample sets. Otherwise, the test results are polluted.
- There must not be a rushed, forced or unusual environment in which the sample sets were developed.
More about the actual statistical tests:
- Both samples together must, each, successively meet these statistical tests:
- The adjectives below that are wrapped with “quotes” are subject to tuning parameters.
- There must be “enough” source characters in each sample.
- Definition: A HALLMARK is a derived metric from group of typed characters (spaces included, as may happen).
- INTRA-sample hallmark consistency is required. Less than 20% of all hallmark candidates will be used. This is a factory setting which tuning could subsequently adjust.
- There must be “enough” hallmarks each sample.
- Hallmarks must represent a “sufficient” percentage of overall typing in each sample.
- There must be “enough” overlapping hallmarks between ALL samples (hence the advice above not to include too many samples in any single run).
- There must be “sufficient” combined hallmarks as a percentage of overall sample size for ALL samples.
Topics relating to reducing “all the output” to a single conclusion:
- Just give me a YES or NO!
- We recognize that the common desire is for a single “win-lose” number. The problem is that there are several types of wins/losses:
- Not enough data is a “lose,” but that does not necessarily mean that the samples were typed by a different person.
- Not enough hallmarks is a “lose” because of statistical insufficiency, but that does not necessarily mean that the samples were typed by a different person.
- Not enough overlaps is a “lose,” but that does not necessarily mean that the samples were typed by a different person.
- Given numerical sufficiency in the above, a single number resulting in a YES/NO opinion can be a good telltale to warrant further/forensic investigation, yet does not necessarily mean that the samples were typed by a different person.
- The various outputted numbers can be further combined to facilitate an automated nomination of a mismatch, which may need to be separately confirmed by other investigative applications or processes. The nomination process is very helpful in that it focuses and speeds those efforts.
Results
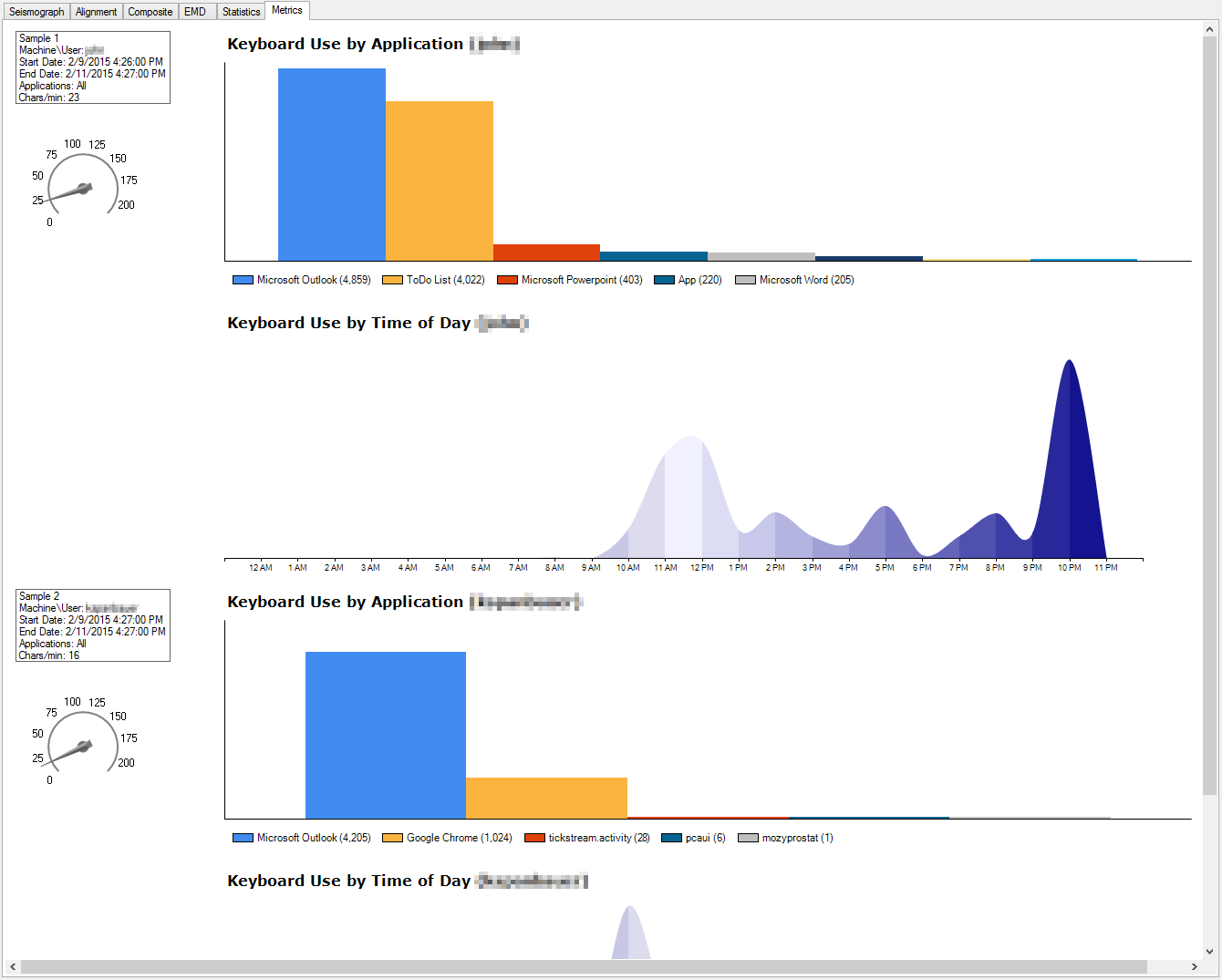
There are seven parts to the TickStream.CV display.
1 Use the Tree control on the left to pick the User/Machine combination. When you have found the pair you seek, double click it to bring up the list of checkboxes on the right. Each checkbox represents an application which executed at some point on the User/Machine pair well the keystroke collection mechanism was active.
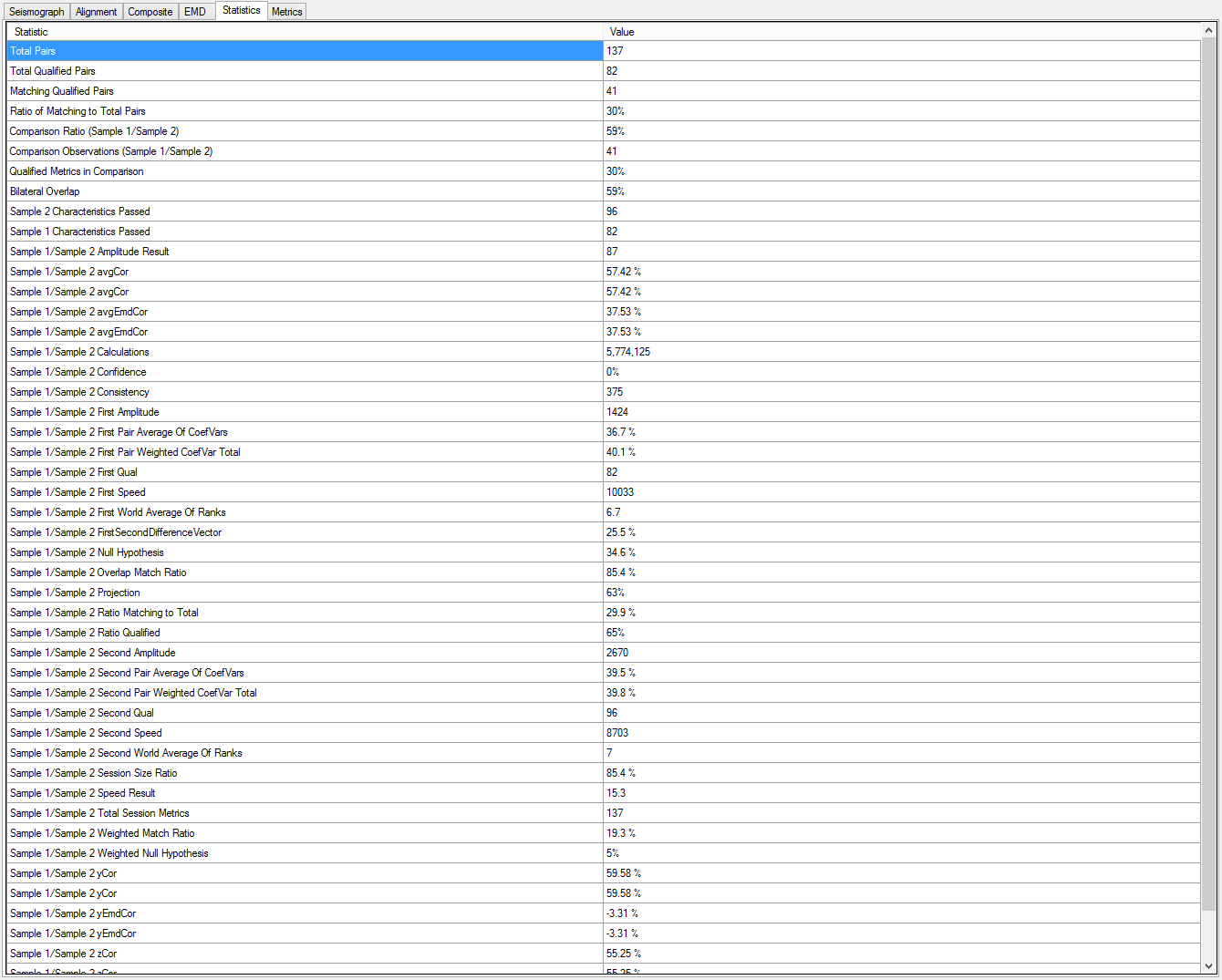
2 This tab contains the raw data of all of the performance metrics created during the process of evaluating every combination of sample sets. Some of these data, particularly the EMD percentages (see output element number six, below), can constitute workable single-number indicators of a likely match.
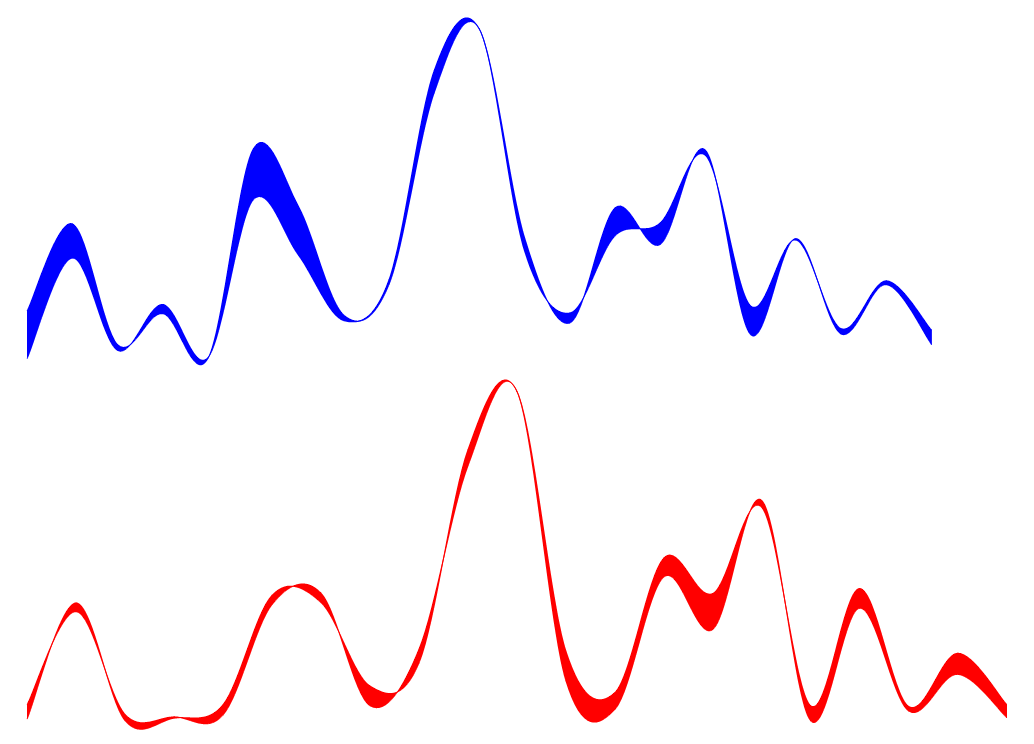
3 This “seismograph” graph displays the behavior patterns across the most significant hallmarks encountered in the samples. No two collections of “squiggles” will ever match, but even a brief glance at these two suggest that they reflect typing efforts of the same person.
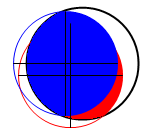
4 The alignment circles reflect the total number of candidate hallmarks (the black circle) and, in this case, the red and blue circles, reflecting (a) the number of hallmarks in each of those two samples, (b) the percent of the total they compose, and (c) the degree of overlap between them.
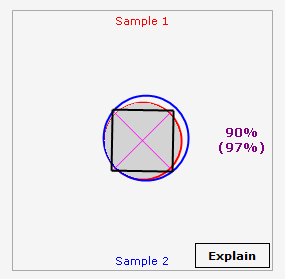
5 This is a compendium of many graphic elements which, together, visually depict the nature of the match between any two sample sets. There is a blue circle, a red circle, a gray overlap zone, a magenta X, a black bounding box (which changes in both size and sheer). There are also two percent numbers which represent IA’s early attempt to depict a series of very complicated statistical computations into numbers which we call “fidelity” and “confidence.” Those two words are ours, and do not arise from formal definitions in the world of statistics. They must be viewed together, and that both ends of the 0-100 spectrum, our “numbers roll up” are quite reliable. Numbers in the 40-60 range reflect uncertainty. There is another attempt to resolve the numerical uncertainty in output element number six. The Explain button is an early attempt to express the results in an automatically-assembled paragraph of text, and is still a work in process.
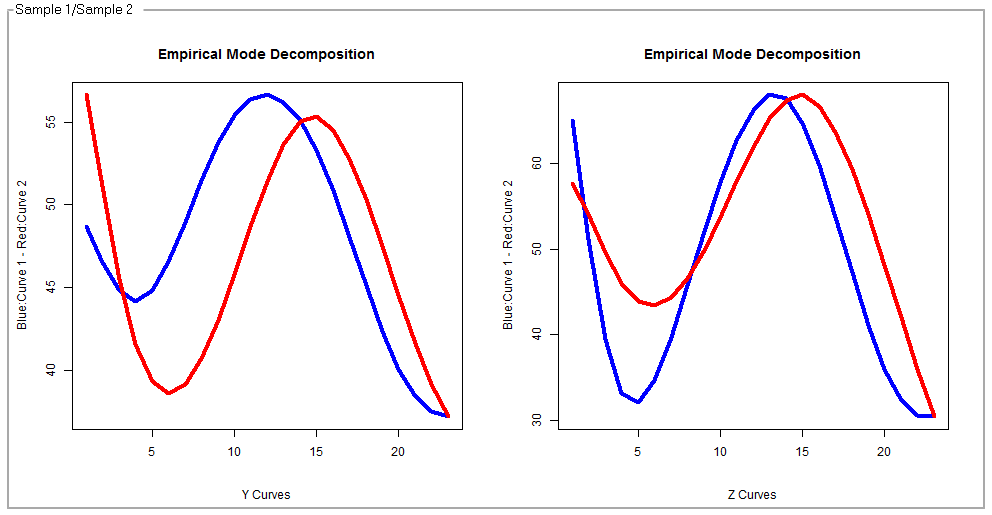
6 Empirical Mode Decomposition represents another attempt to visually compare two sample set efforts by using certain very sophisticated statistical smoothing techniques. We have found that these graphs produce “correlation” numbers, shown below, that are highly reliable single-number statistical opinions.
7 TickStream.CV also has the ability to produce helpful statistics which describe many behavioral traits exhibited during the typing of each of the sample sets. In this example, overall typing speed, as well as the time of day, on a 20 4 o’clock, are shown (although space limitations here prevent seeing the entire picture). In combination with its sister product, Activity, which in this iteration has been joined with TickStream.CV, constituting IA’s Unity Solution, many behavioral mannerisms can be visually portrayed, and easily digitized.